Use Case
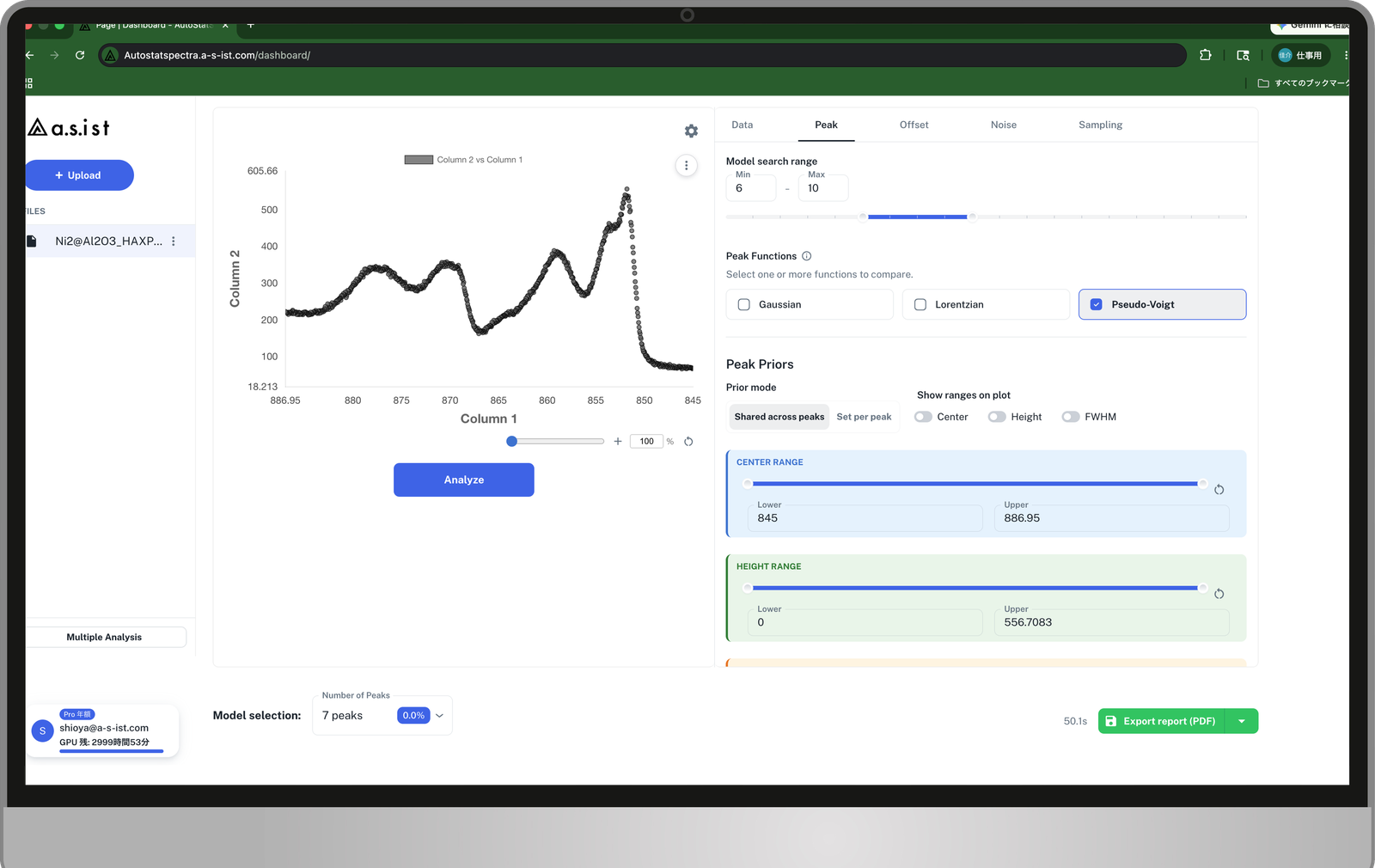
XPSデータの自動解析事例【AutoStatSpectra】
ピーク数を客観的に決定し、初期値依存性を解消した安定したフィッティングを実現。従来の最適化アルゴリズム(LM法)と比較し、より妥当な結果を得られました。
概要
X線光電子分光(XPS)データの解析では、ピーク数の決定とパラメータフィッティングの両方に解析者の経験と判断が要求されてきました。 当社のスペクトル自動解析ソフトウェア AutoStatSpectra は、ベイズ推論を用いることで、ピーク数を客観的に推定し、初期値依存性を抑えた安定したパラメータ推定を実現します。
導入効果
- ピーク数を事後確率に基づき客観的に決定
- 初期値依存のないパラメータ推定で再現性を確保
- パラメータの不確かさを事後分布として定量化
本手法の3つの優位性
同一の Ni / Al₂O₃ HAXPES データに対するベイズ推論(AutoStatSpectra)と従来手法(LM法 + BIC、マルチスタート)の解析結果を要点で比較しました。
① ピーク数を客観決定
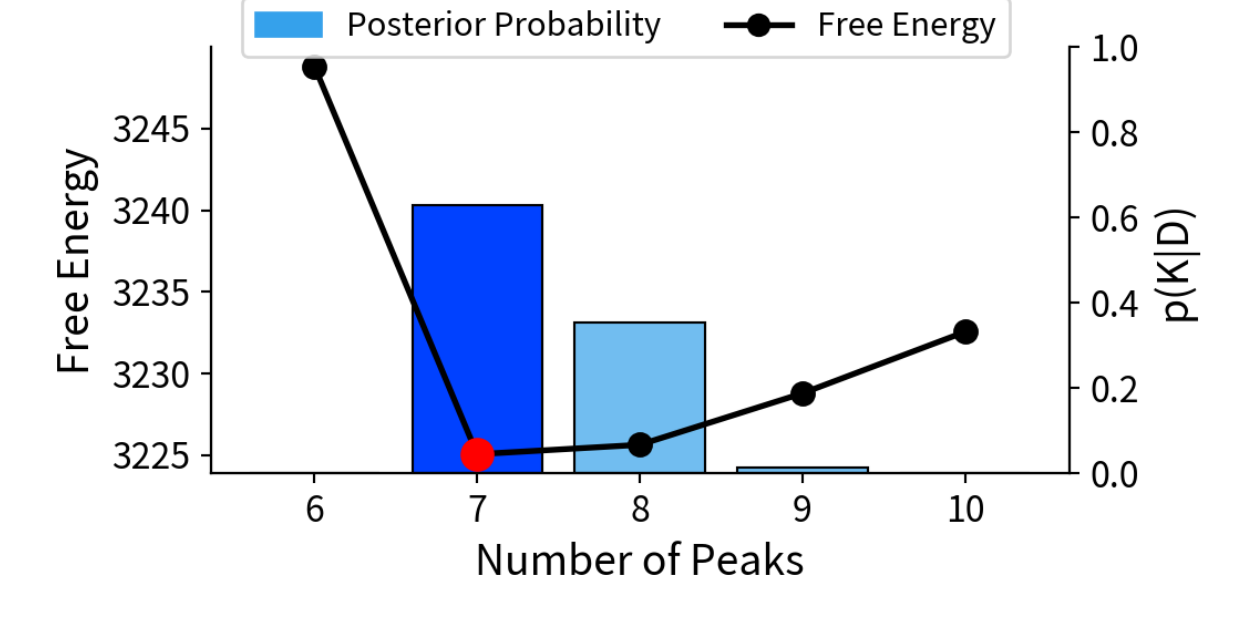
事後確率に基づき K = 7 を選択。
従来手法(LM + BIC)は K = 9 と過大評価。
② 初期値依存性を低減
事前分布から探索することで 安定したフィッティング。
従来のLM法は マルチスタート8回でも破綻するケースが発生。
③ 不確かさを定量化
パラメータの事後分布から信頼区間・標準偏差を取得。
従来手法は 結果の信頼度評価が困難。
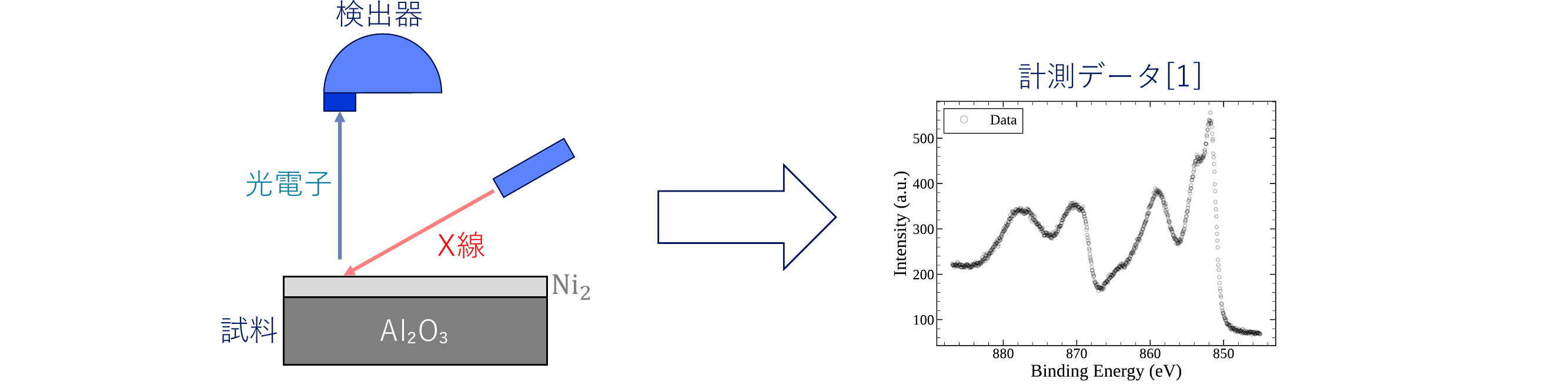
対象データ
酸化アルミニウム(Al₂O₃)上に担持した Ni 試料に対する硬X線光電子分光法(HAXPES)データを対象に、ピーク数推定とパラメータ推定をベイズ推論によって行いました。
- 試料:Ni / Al₂O₃
- 測定手法:硬X線光電子分光(HAXPES)
- 解析対象:Ni 2p 領域(約 850〜890 eV)
- データ出典:公開データセット(CC BY 4.0、下記参照)
本手法:AutoStatSpectra によるベイズ推論解析
ピークの数理モデル(ガウス・ローレンツ混合 + Shirley バックグラウンド)とノイズモデル(ポアソン近似 + 系統誤差)を用い、ピーク数 K とモデルパラメータ Θ を同時にベイズ推論で推定します。
ピーク数の事後確率推定
ピーク数の候補 K = 6〜10 について自由エネルギーを計算し、事後確率に基づいて最も妥当なピーク数を決定します。本事例では K = 7 が事後確率 63.06% で最も支持され、K = 8(35.39%)も含めた不確かさが可視化されています。
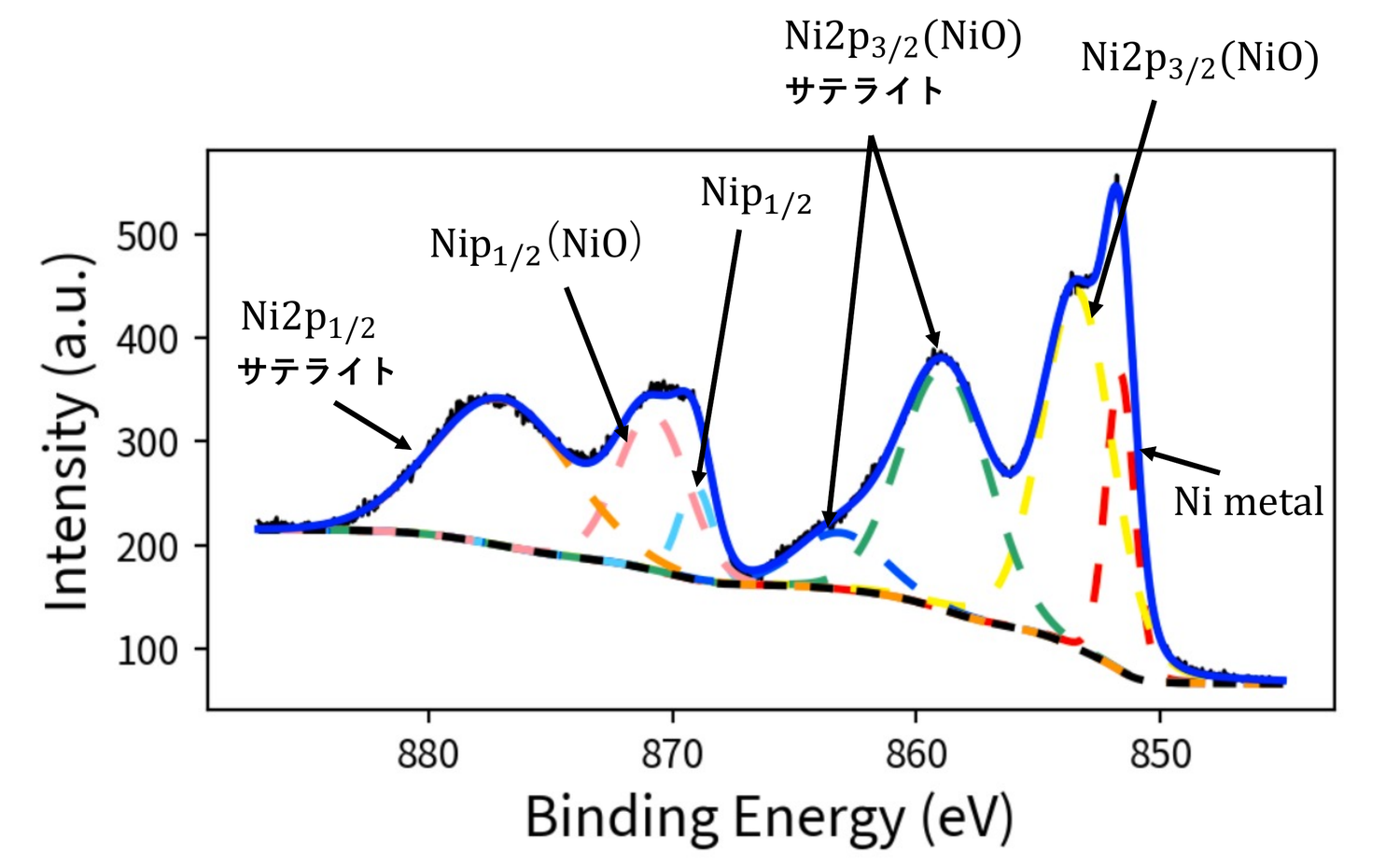
元素種・化学状態の同定
推定された7本のピーク位置から、Ni metal、Ni2p3/2(NiO)、Ni2p1/2(NiO)、それぞれのサテライト構造を同定。
得られる情報
- ピーク位置 → 元素種と化学状態の同定
- ピーク面積 → 元素比・相割合
- ピーク線幅 → 導電性など物性情報
- パラメータの事後分布 → 信頼度・不確かさ評価
従来手法(LM法 + BIC)との比較
同じデータに対して、一般的なパラメータフィッティング手法である Levenberg–Marquardt(LM)法と BIC によるピーク数選択を適用し、本手法と比較しました。
過大なピーク数推定とフィッティングの不安定性
BIC 基準では、LM 法によるフィッティングで K = 9 が選択され、ベイズ推論で支持された K = 7 よりもピーク数を多く見積もる結果となりました。また、LM 法は初期値依存性が強く、マルチスタート(8回)を適用しても フィッティングが破綻する事例が確認されました。
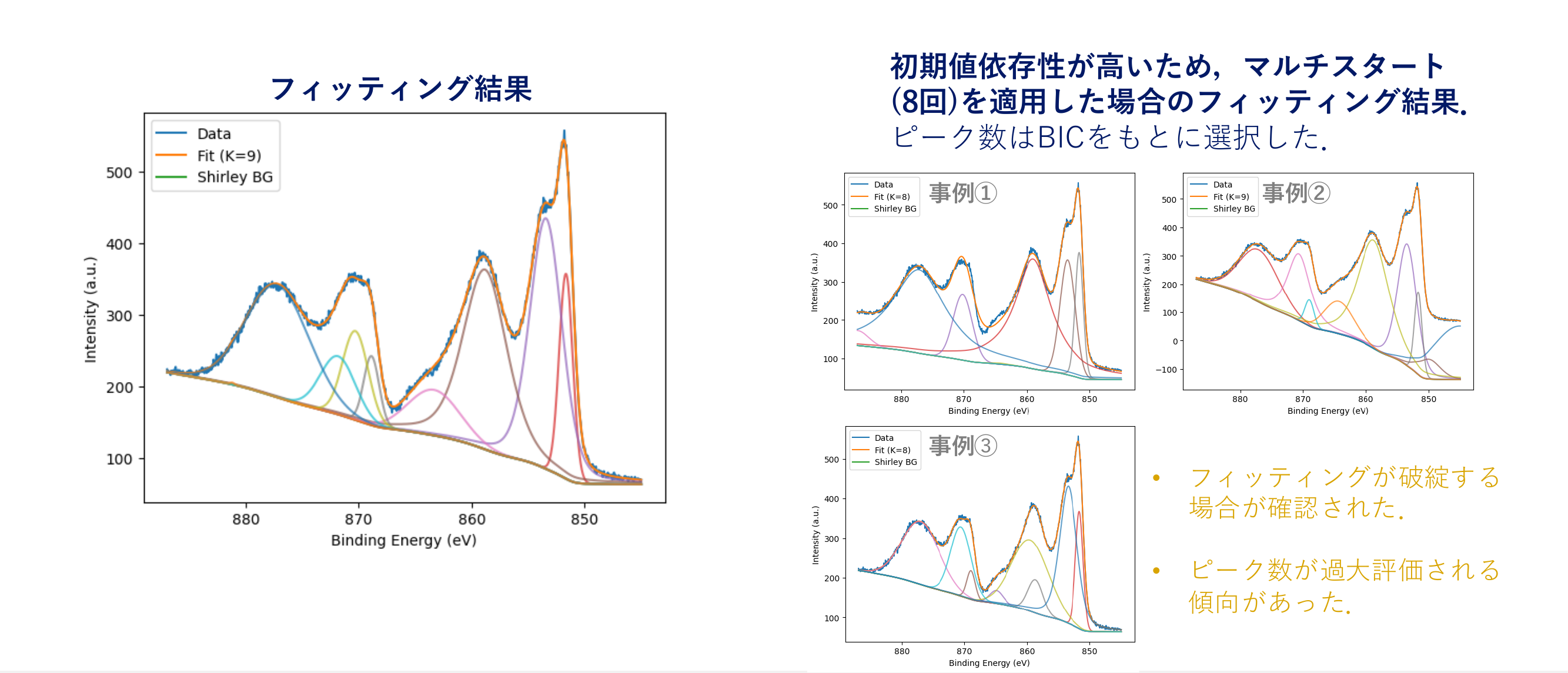
このように従来手法では、ピーク数選択とパラメータ最適化の両方で結果が不安定になりました。一方、本手法ではピーク数とピーク形状を確率的に評価することで、より解釈しやすい推定結果が得られます。
従来手法(LM法 + BIC)
- ピーク数を過大評価する傾向(K=9)
- 初期値依存性が高く、マルチスタートが必要
- フィッティングが破綻する事例あり
- 結果の信頼度評価が困難
本手法(ベイズ推論)
- ピーク数を事後確率に基づき決定(K=7)
- 初期値依存性が小さく安定
- パラメータの事後分布から不確かさを定量化
- 解析者の経験への依存度を低減
まとめ
一般的な解析手法では、ピーク数の推定値が過大評価される傾向や、フィッティング結果が破綻する場合がしばしば見られました。これは、よく知られた試料や熟練の解析者であれば人手によって取り除ける結果ではあるものの、結果の信頼度評価が難しいという課題として残ります。
本手法(ベイズ推論)は、ピーク数とパラメータの両方を確率的に推定することで、解析者の経験に依存しない再現性のある解析を実現します。高速で簡便な従来手法とベイズ推論を適材適所で組み合わせることで、効率的かつ信頼性の高いスペクトル解析が可能となります。
お問い合わせ
XPS、XRD、ラマンなど、各種スペクトルデータのベイズ推論による自動解析をご提案します。
- 装置・データ形式に合わせた解析テンプレートの整備
- 既存解析プロセスとの並行検証(PoC)
- 解析レポートの自動生成と現場運用への組み込み